TOSAI projectUnderstanding and Creating Dynamic 3D Worlds towards Safer AI |
| NewsPeoplePublicationsCodeAbout |
Publications |
|

|
DeePoint: Visual Pointing Recognition and Direction EstimationShu Nakamura, Yasutomo Kawanishi, Shohei Nobuhara, Ko Nishino ICCV, 2023 arxiv / code / We introduce the first neural pointing understanding method based on two key contributions. The first is the introduction of a first-of-its-kind large-scale dataset for pointing recognition and direction estimation, which we refer to as the DP Dataset. DP Dataset consists of more than 2 million frames of 33 people pointing in various styles annotated for each frame with pointing timings and 3D directions. The second is DeePoint, a novel deep network model for joint recognition and 3D direction estimation of pointing. |
|
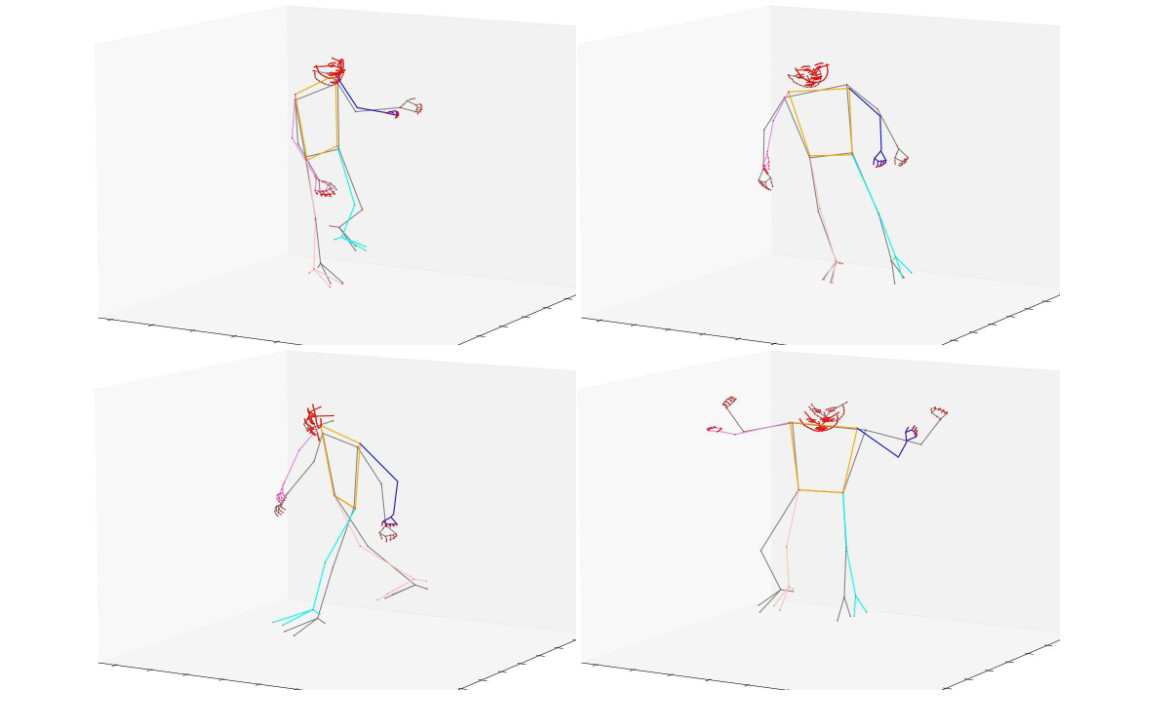
H3WB: Human3.6M 3D WholeBody Dataset and BenchmarkYue Zhu, Nermin Samet, David Picard ICCV, 2023 arxiv / code / 3D human whole-body pose estimation aims to localize precise 3D keypoints on the entire human body, including the face, hands, body, and feet. We introduce Human3.6M 3D WholeBody (H3WB) which provides whole-body annotations for the Human3.6M dataset using the COCO Wholebody layout. H3WB is a large scale dataset with 133 whole-body keypoint annotations on 100K images, made possible by our new multi-view pipeline. Along with H3WB, we propose 3 tasks: i) 3D whole-body pose lifting from 2D complete whole-body pose, ii) 3D whole-body pose lifting from 2D incomplete whole-body pose, iii) 3D whole-body pose estimation from a single RGB image. We also report several baselines from popular methods for these tasks. |
|
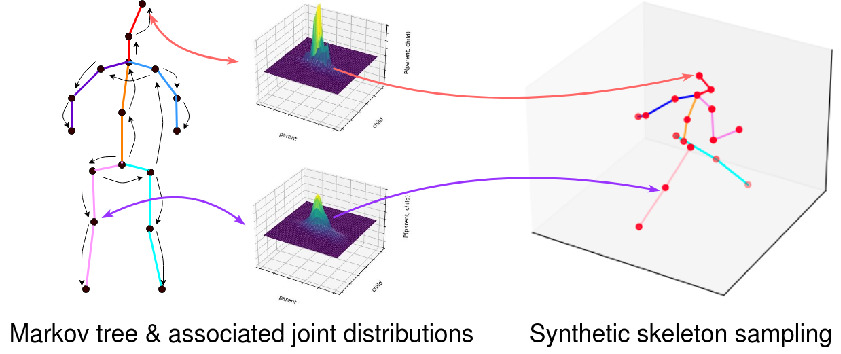
Decanus to Legatus: Synthetic training for 2D-3D human pose liftingYue Zhu, David Picard ACCV 2022, 2022 arxiv / code / We propose an algorithm to generate infinite 3D synthetic human poses (Legatus) from a 3D pose distribution based on 10 initial handcrafted 3D poses (Decanus) during the training of a 2D to 3D human pose lifter neural network. Our results show that we can achieve 3D pose estimation performance comparable to methods using real data from specialized datasets but in a zero-shot setup, showing the generalization potential of our framework. |

|
Neural Head Avatars from Monocular RGB VideosPhilip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Nießner, Justus Thies CVPR 2022, 2022 arxiv / code / We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. Our representation can be learned from a monocular RGB portrait video that features a range of different expressions and views. Specifically, we propose a hybrid representation consisting of a morphable model for the coarse shape and expressions of the face, and two feed-forward networks, predicting vertex offsets of the underlying mesh as well as a view- and expression-dependent texture. We demonstrate that this representation is able to accurately extrapolate to unseen poses and view points, and generates natural expressions while providing sharp texture details. Compared to previous works on head avatars, our method provides a disentangled shape and appearance model of the complete human head (including hair) that is compatible with the standard graphics pipeline. Moreover, it quantitatively and qualitatively outperforms current state of the art in terms of reconstruction quality and novel-view synthesis. |
|
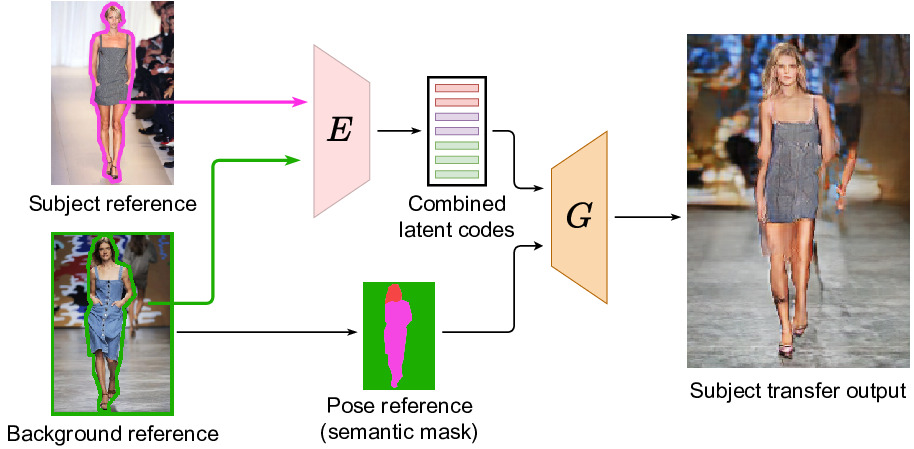
SCAM! Transferring Humans Between Images with Semantic Cross Attention ModulationNicolas Dufour, David Picard, Vicky Kalogeiton ECCV 2022, 2022 arxiv / code / We introduce SCAM (Semantic Cross Attention Modulation), a system that encodes rich and diverse information in each semantic region of the image (including foreground and background), thus achieving precise generation with emphasis on fine details. This is enabled by the Semantic Attention Transformer Encoder that extracts multiple latent vectors for each semantic region, and the corresponding generator that exploits these multiple latents by using semantic cross attention modulation. It is trained only using a reconstruction setup, while subject transfer is performed at test time. Our analysis shows that our proposed architecture is successful at encoding the diversity of appearance in each semantic region. |
|
|


